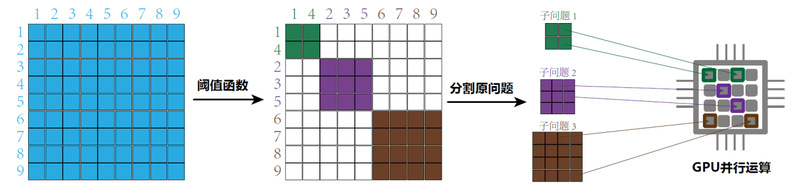
随着大数据时代的到来,很多应用在使用中收集了大量的数据。然而大规模数据却使得应用后端模型的计算成本大幅增加,因此如何快速训练模型成为了使用机器学习进行大规模数据处理的一大挑战。近年来,针对于基于概率图模型预测数据变量之间相关性的问题,人们提出了许多快速处理大规模数据的模型。然而它们仍然具有运算成本很高的步骤,例如奇异值分解与线性规划问题求解。为了解决大规模数据处理的挑战,我们提出了基于模型分隔理论的元估计量(elementary estimator)模型,并由此提出了本文的FST模型。FST首先利用阈值函数对数据进行稀疏化处理,然后将原问题分割成多个独立的子问题,最后利用GPU并行解决子问题,从而大幅减少了计算成本。我们的FST模型对于数据变量相关性预测具有较高的准确度和较低的运算时间。具体来说,相比于之前的模型,FST模型对于百万数量级的变量相关性预测可以得到至少2倍的加速。与此同时,FST预测结果的误差也得到了大幅的降低。我们的实验还证明,对于不同结构的概率图模型,FST都能得到很好的预测结果。大量实验表明,FST模型具有良好的性能。
本研究由东南大学在本项目支持下完成,结果发表在CCF推荐A类国际会议IJCAI 2020上。