随着人工智能的快速发展,深度学习作为人工智能中的核心技术广泛应用于各行各业。然而,训练深度学习模型通常是计算密集型任务,因此,一方面越来越多的硬件公司试图不断提升GPU性能,同时研究者们致力于研究分布式代替传统单机方式提高训练效率,以加速训练过程。然而,现阶段的分布式训练方法由于未考虑流水线训练方式及GPU集群间的异构网络,可获得的加速比仍然是有限的。我们根据GPU集群间异构网络拓扑,结合深度神经网络的特点,提出了流水线负载均衡的模型划分机制及动态规划算法,然后基于Alexnet,Inception_v3,Resnet50,Vgg16等典型的深度神经网络模型,在东南大学GPU集群环境中进行了实验。实验结果表明,在未损失训练准确率的前提下,本方法较传统的数据并行(data parallel)训练方法,可获得近2倍的加速比。
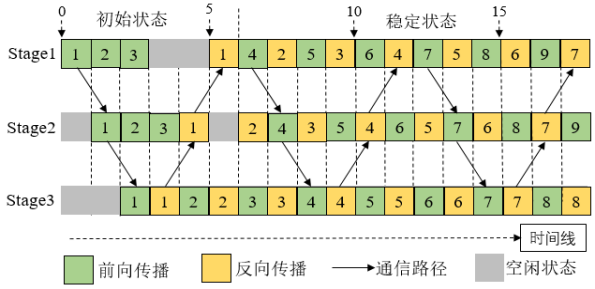
本研究由东南大学在本项目支持下完成,结果发表在CCF推荐C类国际期刊Concurrency and Computation: Practice and Experience上。
